I am delighted to announce the launch of a new website for legal recruitment agency G2 Legal.
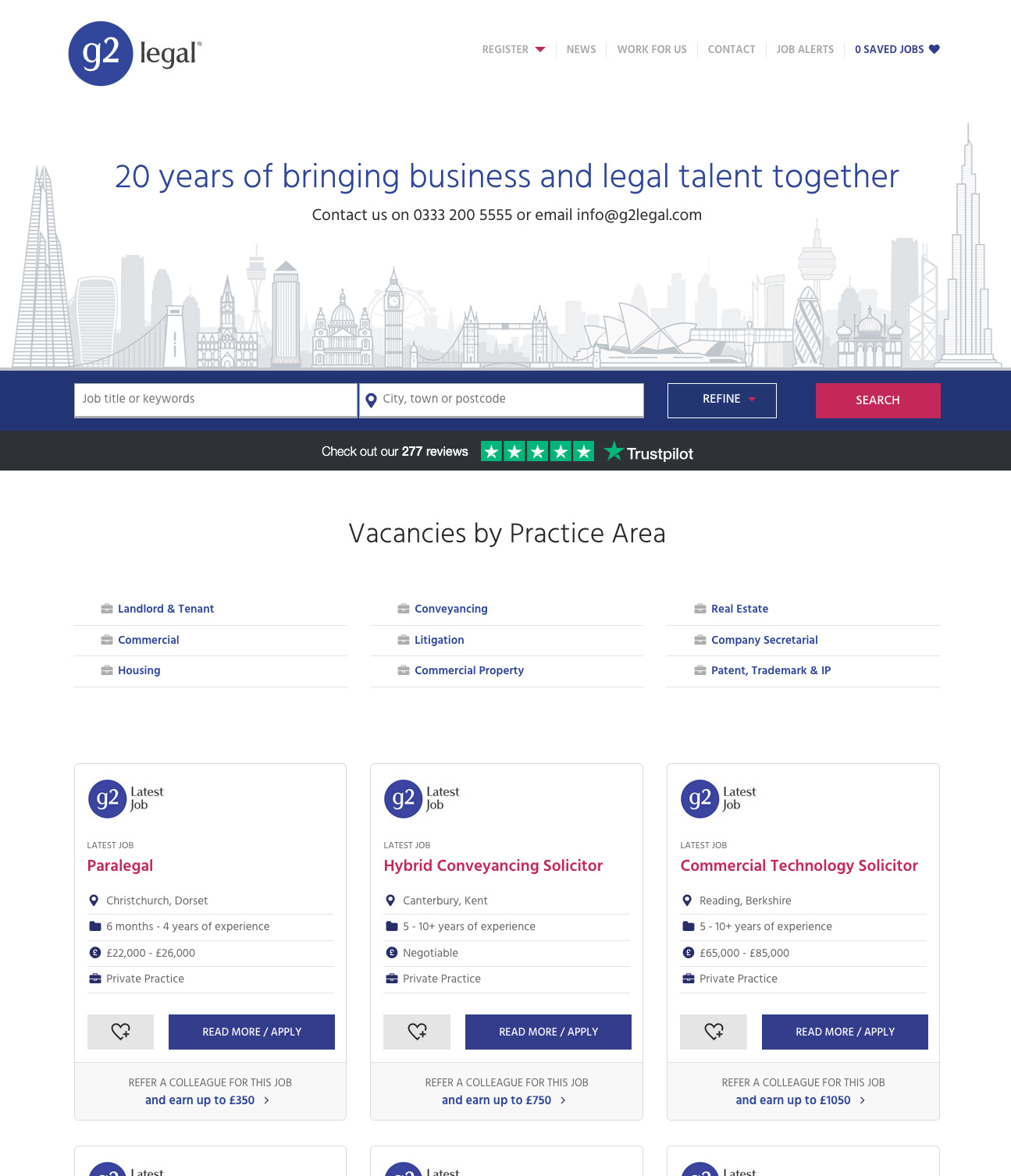
 The G2 Legal website from 2017-2024 |
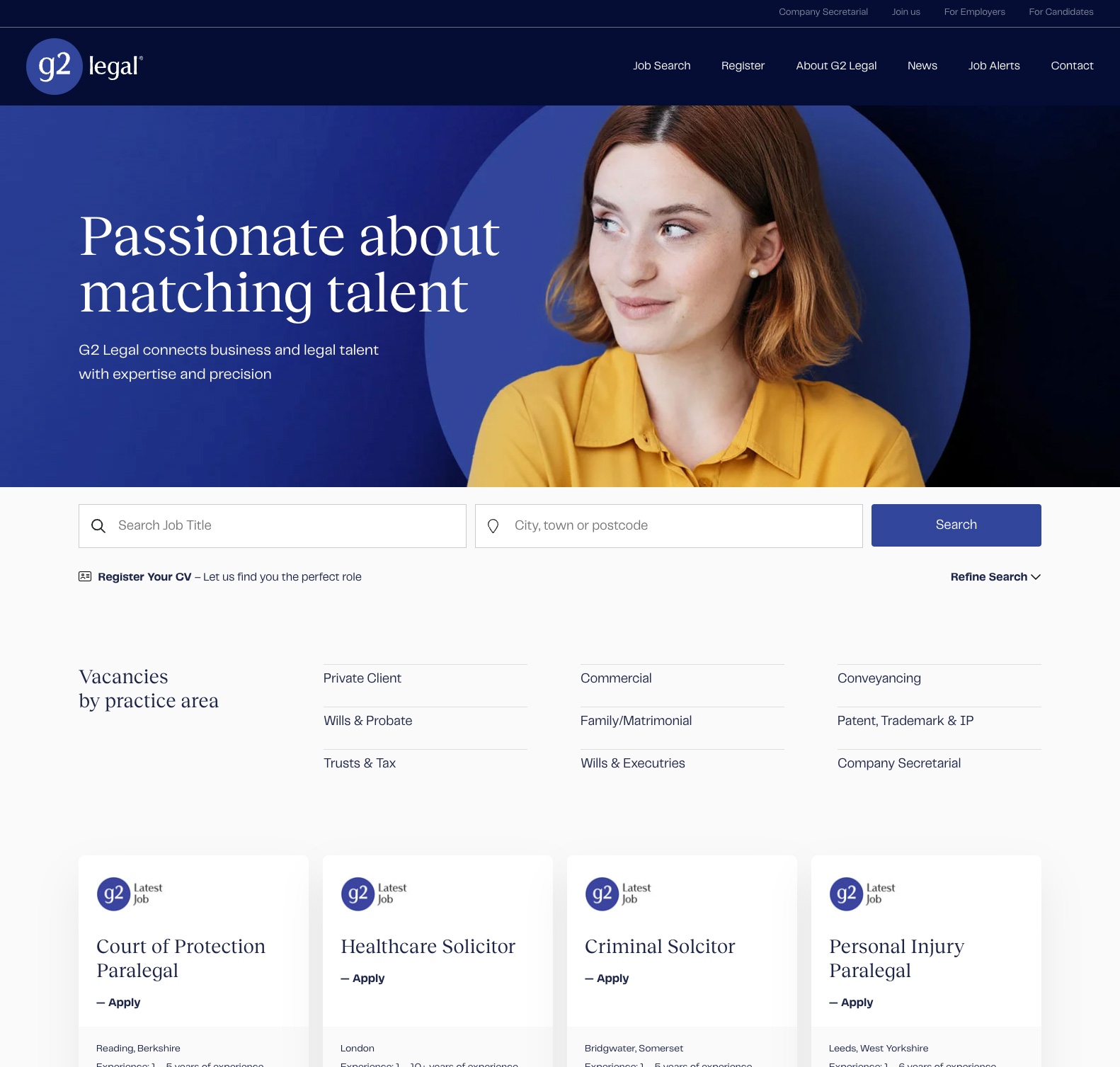
 The new G2 Legal website (click for larger) |
I have a very long relationship with G2 Legal, this is the seventh complete website I’ve helped build for them and it was very much a group effort.
The Team
Amy Walker – Head of Marketing at G2 Legal – acted as primary contact and driver of the project. She handled researching and collating all of the company needs, boiling them down to the necessities and messages that can fit on a website, writing all of the content, and a huge amount of project management. This website does a great job of representing the company, and that is down to her and the work she put in both with Nick and the whole project.
Nick Carter – Studio Gallant – design and UX. Nick is a fantastic designer and I’ve collaborated with him on several websites for clients. As usual, he did a fantastic job of taking the client brief and making a design that is contemporary, professional, and will stay fresh for many years. He worked closely with Amy to make sure G2 Legal got what they needed from this project and I think he did a very, very good job.
Jim Lester – Zero1Zero – front end build. Jim came highly recommended by Nick and I can see why. He made a great translation of Nick’s designs into working templates with clean, understandable HTML, CSS and Javascript in short order and was more than helpful when we had some late additions to the project. He was a delight to work with and I hope I get a chance to again in the near future.
Paul Silver – Silver Web Services – back end build, integration of front and back ends. More on my part below, but in brief I handled moving the website from one set of back end code to another, took Jim’s templates and turned them into a working site which can be edited by the staff at G2 Legal, and handled various search engine optimisation tasks.
The site became a much larger project than planned and I am delighted with the way it has come out. Thank you to everyone who was involved with the project, I hope you’re as proud of the outcome as I am.
My part of the project
Laravel to WordPress
Being a programmer, most of my work is hidden away. Previous versions of the website were editable by the staff at G2 Legal, but the content management features were little used and had therefore not had much in the way of updates for over ten years. Now, the company has an active marketing department headed by Amy and the website needed to change. Their main requirement from the tech was to have a site they could easily edit and preview changes so they could see the pages as they would be published, not just parts of them.
The previous site was based on Laravel and various custom code written by myself and Laura Tyler. I assessed various Laravel based Content Management Systems (CMS) to see what we could add to the existing code base to do what was required, but I found them all rather lacking from a user experience viewpoint. The people updating the website are not techies and should not need to become ones in order to get their job done. I looked further afield for better tech.
WordPress for a modern editing experience
A solution came thanks to Hazlitt Eastman, who showed me a project he was making in WordPress using their latest editor with helpful additions from Advanced Custom Fields. It gives the site owner a very good editing system and preview and allowed me to get very close to the perfect experience for the client within their budget. Hazlitt kindly gave me a training session in how to set up the “blocks and patterns” involved in making the editing system pleasant to use and extra technical support across the project. Big thanks to Hazlitt for this, he got me out of several technical holes.
A lot to port
Originally I was thinking I’d use Laravel to run an API which the WordPress site would make requests to. For most of the site, that turned out not to be the right choice when I looked at the long term maintainability of the code, and considering at some point they may want another developer to work on the project. So, most of the backend code moved from Laravel to WordPress style PHP. The site may look simple, but there are a lot of hidden depths to it, including a very advanced job search both on the backend and with a new experience on the frontend which meant writing new APIs, which WordPress easily handled, and a lot of Javascript.
The intricacies of moving all of the code was a much larger task than I expected, but I think gives us advantages over the short and long term: the speed of response of the website wouldn’t have been as fast if I had stuck with my original plan, and changes over time would have been more convoluted as we’d be working with two quite different styles of codebase rather than just one within WordPress.
Looking at the long term
The previous website was live for a little over six years and went through many changes as company needs changed. It ended up as a bit of a patchwork of the original and new looks and features. I’m confident this site is flexible enough to work with changes G2 Legal needs over the coming years and will still look good at the end of it.
Hear’s to Amy, Nick and Jim for all the help getting it there with me.